10.2
尚硅谷mysql基础篇看完就忘了。基础的语法内容需要一定的代码量,最近我会多敲敲mysql。
SQL背景:
最重要的 SQL 标准就是 SQL92 和 SQL99。一般来说 SQL92 的 形式更简单,但是写的 SQL 语句会比较长,可读性较差。而 SQL99 相比于 SQL92 来说,语法更加复杂, 但可读性更强。SQL92 和 SQL99 是经典的 SQL 标准,也分别叫做 SQL-2 和 SQL-3 标准。
表连接区分
内连接、外连接
inner join内连接:满足交集。outer join: 左右外连接。
内外连接即交并集的关系。
自连接 、 非自连接
- 自连接:对某个表来说,自己和自己的数据进行匹配。
- 非自连接:非自连接要借助外表。
联结/连接区分
联结、高级联结
- 等值联结(内部联结):
1 | SELECT * |
- 多表联结:
1 | SELECT * |
自联结(自己和自己的两个表进行联结),即自连接
自然联结:如下
NATRUAL JOIN外部联结 LEFT / RIGHT
JOIN(内连接,外连接)
组合查询:UNION
子查询
表查询区分
等值查询、非等值查询
等值查询:过滤条件里是否为数值上的相等关系
非等值:BETWEEN ON,模糊查询
相关(关联)查询、非相关(非关联)查询
关于关联子查询:
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联。
因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为 关联子查询 。
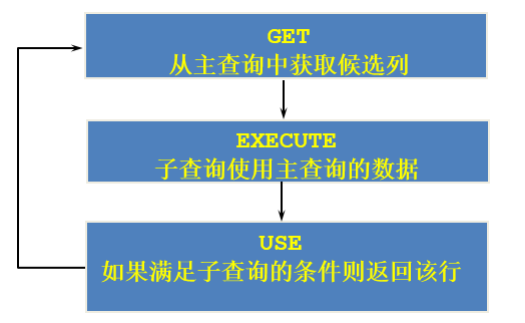
题目示例:
不相关子查询:
查询员工中工资大于本公司平均工资的员工的last_name,salary和其department_id
相关子查询:
查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id
PS:公司平均工资和该员工的个人信息没有关系,即不相关。
部门和该员工的个人部门有关,相关。
另:多表查询是个很大的范围,用到两个表以上的查询就是多表查询。
函数区分
单行函数、多行(分组、聚合)函数
单行函数
- 操作数据对象
- 接受参数返回一个结果
- 只对一行进行变换
- 每行返回一个结果
- 可以嵌套
- 参数可以是一列或一个值、
多行函数
聚合函数作用于一组数据,并对一组数据返回一个值
表连接的新语法
自然连接:
类似 SQL92 中的等值连接:自动查询两张连接表中所有相同的字段来进行等值连接
在SQL92标准中:
1 | SELECT employee_id,last_name,department_name |
在 SQL99 中你可以写成:
1 | SELECT employee_id,last_name,department_name |
USING连接
SQL99支持使用 USING 指定数据表里的同名字 进行等值连接。USING只能配合JOIN一起使用。
区别于自然连接 ,USING 指明了相同的字段名称,同时使用 JOIN…USING 可以简化 JOIN ON 的等值连接。
1 | SELECT employee_id,last_name,department_name |
1 | SELECT employee_id,last_name,department_name |
上面两者效果相同。
这里 using 取代了 WHERE 的作用,并且形式上更简洁。
表连接的约束条件可以有三种方式:WHERE, ON, USING
WHERE:适用于所有关联查询
ON :只能和JOIN一起使用,只能写关联条件。
虽然关联条件可以并到WHERE中和其他条件一起写,但分开写可读性更好。
USING:只能和JOIN一起使用,而且要求两个关联字段在关联表中名称一致
只能表示关联字段值相等
N张表关联时的效率问题:
1 | #n张表关联,需要n-1个关联条件 #查询员工姓名,基本工资,部门名称 SELECT last_name,job_title,department_name |
我们要控制连接表的数量。多表连接就相当于嵌套 for 循环一样,非常消耗资源,会让 SQL 查询性能下降得很严重。
在许多 DBMS 中,也都会有最大连接表的限制。
【强制】超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时, 保证被关联的字段需要有索引。
说明:即使双表 join 也要注意表索引、SQL 性能。
来源:阿里巴巴《Java开发手册》
优化sql查询语句的思路:一次查询返回多个需要的column
注意 DISTINCT , IS NOT NULL 的情况。
FROM 后的表和别名更容易维护扩展。
实际上,很多
WHERE处的过滤条件,都可以通过在FROM处改动来替换
例子:
无别名
1 | SELECT * |
有别名
1 | SELECT last_name, department_id, email, salary |