第四章 Function 语意学 (The Semantics of Function)
前言:
1 | float Point3d::magnitude()const { |
下面我们进行操作:
1 | Point3d obj; |
这里还无法确定实际的操作。
C++支持三种函数调用:static func , nontatic func , virtual func 。
每种方式都不同,也是我们接下来要区分的。
这里可以确定 normalize() 和 magnitude() 两函数绝不是 staic。
原因:
- 可以直接存取 nonstatic 数据
- 它被声明为了const
注释:static 数据没有隐式 this 指针,同理 static 成员不是任何对象的成分(元素),没有 const 对应的“不修改所属对象的成员属性”一说。
4.1Member 的三种调用方式
Nonstatic Member Function
1.nonstatic 成员函数至少和 nonmember function 有相同效率
达成这个效果,是因为编译器内部已将 成员函数 转换成了对等的 non-member 函数
举个例子吧:
1 | float magnitude3d(const Point3d *_this) { |
反差:利用 this 指针 不断间接取用坐标成员好像降低了效率,不同于非成员函数的直接取用。
转化步骤:
改写函数原型(signature),安插一个 this指针 作为额外参数到成员函数中,从而使类对象被直接调用。
const 成员函数,其额外参数 this 指针同样是 const *this pointer。
将后续操作中涉及存取 nonstatic data member 的,改为通过 this 指针存取。
1
2
3return sqrt(_this->_x*_this->_x +
_this->_y*_this->_y +
_this->_z*_this->_z);将成员函数重新写成一个外部函数
为了防止重名,函数名会经过 mangling 处理,成为绝不会重名的词。
1
extern magnitude__7Point3dFv( register Point3d *const this);
成员函数转换为外部函数,意味着调用操作也完成了转换:
obj.magnitude();变成了magnitude__7Point3dFv(&obj);ptr->magnitude();变成了magnitude__7Point3dFv(ptr);
这时回到原题:normalize函数的调用问题。
1 | //伪码 |
这是转变情况之一。
另外一种情况是利用Point3d的构造函数构造匿名对象简化操作:
1 | Point3d::Point3d::normalize()const { |
转化(假设拷贝构造相关操作已完成,NRV优化^1也已实现):
1 | void normalize__7Point3dFv(register const Point3d *const this, Point3d &__result) { |
节省了默认构造初始化的额外负担。
2.名称的特殊处理(Name Mangling)
编译器的处理下,通常成员名称前会被加上类名称。
1 | class Bar{public: int ival;} |
- Name Mangling的原因:便于区分重名变量。
1.子类继承时重名
1 | class Foo:public Bar{public:int ival;} |
子类Foo和父类发生成员变量重名的情况;编译器为了区分会处理名称:
1 | class Foo { |
2.成员函数重载时重名
1 | class Point { |
简单转换为
1 | class Point { |
这就是cfront的编码方法。目前还没有Name Mangling 的工业标准统一这一行为。
Name Mangling 能实现有限的类型检验:
声明和定义两部分参数类型不一致的函数,会产生不同的编码名称,这就会导致链接时期无法 resolved 而失败。
有限之处在于它只能涉足函数签名(signature),不能检测返回值。
拓展:
现在的编译系统中,有一种 demangling 工具,能把编码后的名称转换回去。这个系统内会存储两种名称:”mangled 之前“和”mangled 之后”。
**这会导致一种误导行为:**编译器错误信息提示时,使用源码名称;链接器却使用编码后的内部名称。
把内部名称(mangled 编码后)给 user 看会让 user 一头雾水。
Virtual Member Function
第三章讲过,如果normalize()是个虚拟成员函数:
1 | ptr->normalize() |
vptr : 指向 virtual table 的指针,由编译器产生安插在 virtual function -involved class 中。
vptr也会被 name mangling 处理。
1 是 virtual table slot 索引值,关联到 normalize
第二个 ptr 表示 this 指针。
这里还不是最终版本,因为这段代码还有值得优化的地方:
在上面的 code segmeng 中,magnitude() 是在 normalize() 中被调用的,后者由虚拟机制 resolved 后,可以直接显式调用 Point3d 实例中的 magnitude 函数。
大家都在一个类中,我又处在你的作用域里。
1 | register float mag=Point3d::magnitude(); |
还可以继续优化:将 magnitude() 声明为 inline 函数。这样一来代码会变成:
1 | reginster float mag = magnitude__7Point3dFv(this); //mangled name! |
通过 this 指针指出对象所在位置的同时调用虚函数,resolve 的状态会和非静态成员函数一样!
另外,对于函数 obj.normalize()转换成(* obj.vptr[1])(&obj)的意义不大。
因为这个情况中的类对象并不支持多态,所以通过 obj 实例调用的函数只能是 Point3d::normalize()。
通过类对象调用虚函数,会被编译器如同对待非静态成员函数一样,迅速完成 resolved ,成为带对象参数的普通函数调用。
此时,这个虚函数还成为了 inlined function 实例,能够在后续应用中广泛扩展,提高效率。
1 | obj.normalize(); //not to (* obj.vptr[1])(&obj) |
Static Member Function
1 | //如果Point3d::normalize()是一个static member function,以下两个调用操作: |
对静态成员函数的处理,要分为“引入静态成员函数前”(cfront2.0引入)和引入后。
1.引入前的处理:
抛开上面的例子,看一个很有特点的函数形式:
1 | ((Point3d*) 0 )->object_count(); |
这种函数形式出现的原因:
引入…前,CPP要求所有的成员函数都必须通过对应类的实例对象来调用。
这也是 this 指针的重要作用之一
this 指针把 ==在成员函数中存取的非静态成员== 绑定在了 ==类对象内的相应成员==上。
但事实上:
只有当成员函数中,存在非静态成员变量的存取时,才需要类对象。
其他情况根本用不到 class object 。
成员函数如果没有成员被存取,那么它压根就不需要 this 指针。也没有必要强行要求通过一个类对象的实例来调用这个成员函数。
这种情况下,如果设计者把静态成员变量声明为 非public ,他就必须提供很多成员函数来存取这个成员变量。
这时,即使静态成员变量不需要类对象去存取,可对应的存取函数还是需要类对象,这就是一种无奈的绑定关系。
所以脱离类对象的一些存取操作还是很重要的。上面的奇葩函数形式就是这种脱离需求下的产物:
1 | ((Point3d*) 0 )->object_count(); |
这时,为了让独立于类对象的一些存取函数操作更自然:静态成员函数引入了。
2.引入后的处理
我们来看看引入的静态成员函数特性:
- 没有 this 指针。
- 不能直接存取所属类中的非静态成员。
- 不能被声明为 const、volatile、virtual。
- 不需要通过类成员去调用。
首先关于静态成员函数的“.”语法(打官腔叫“member selection”),编译器是这样处理的:
1 | //类成员实例的直接调用: |
name mangled 效果:
2
3
4
5
6
7
8
return _object_count;
}
//converse to
unsigned int object_count__5Point3dSFv() {
//额,这里的SFv表示它是一个static member function,拥有一个void(空白)的参数
return _object_count__5Point3d;
}
取地址
如果此时你想取一个 静态成员函数 的地址,将获得其在内存中的地址。
这和其类成员实例无关,且类型不是指向类成员函数的指针(它和this指针已经没有关系),而是一个实实在在的==非成员函数指针==。
1 | &Point3d::object_count(); |
静态成员函数没有了this指针束缚,效果几乎等同于非成员函数了。
扩展:
一个意想不到的好处:static member function 成为了一个回调函数(callback func)。
这有利于CPP和 C-based X Window 系统的兼容,也可以自然的应用在线程(thread)函数上。
4.2 虚拟成员函数
这一章我们会从头到尾过一遍设计虚函数模型的过程。
老生常谈的模型:一个类,里面有虚表,虚表里存储着虚函数的地址。该类的每个实例对象都会自带一个虚指针,指向这个虚表,来完成多态调用。
执行期多态的实现
既然是虚函数,那么看到这个操作:
1
ptr->z();
你面对的第一个问题便是执行期类型判断(runtime type resolution)。
先从编译期多态的尝试走起:
- 尝试把信息绑定在函数指针上
判断方式里,最自然的想法是将帮助判断对象的信息绑定在ptr身上。
这种策略下,通常一个指针需要的信息有:
它所指向的对象地址
对象类型的编码或者结构信息的地址。
Ps:结构信息是用来分辨对象函数实例的,即help resolved to z()。
这种策略的问题:
- 空间负担
- 和C程序的链接不再兼容。
如果这些额外信息不和指针放在一起,那就只能放在对象(class/struct)的身上了。
类似这种形式:
struct data{ int m,d,y; }(这种形式没有摆脱把信息与指针绑定的弊端)如果为了C兼容性,而要求这种策略只针对class,也不能解决问题。
因为 struct 可能会发生多态,而 class 可能并不需要这些冗余信息。
- 执行期
尝试半天,这个责任还是落到了执行期。所以执行期多态到底怎么实现呢?
多态的定义:
在C++中,多态表示以一个public base class的指针(或引用),寻址出一个derived class object的意思。
1
2
3Point *ptr;
ptr = new Point2d;
ptr = new Point3d;消极多态:
让ptr扮演输送机制的角色,仅仅让基类指针指向子类对象,而没有其他操作。
积极多态:
指出的对象通过指针被使用。
1
2
3
4
5//1.
ptr->z(); //ptr指向了子类
//2.
Point3d *p3d=dynamic_cast<Point3d *>(ptr)
p3d->z();//这就说明是Point3d的_z函数仅仅是这种操作还不够。因为我们无从知晓ptr指向的是基类还是子类或者它有没有实现多态。
结论:
识别一个class是否支持多态,只能看它==是否有虚函数==。只要要虚函数,它就需要额外的执行期信息。
存储的额外信息什么?
现在我们知晓了一个类要实现多态,需要执行期信息来完成正确多态操作。
需要的信息:
- ptr所指对象的真实类型,方便找到正确的实例(如
z() - 对象实例的位置,方便ptr调用
实现:
- 一个字符串或数字来表示类的类型
- 一个指向表格的指针,该表格存储虚函数执行期地址
这时,vptr和 virtual table 很自然的出现了。
剩下的问题是,虚表怎么找到并构建这些地址?
找到地址:虚函数地址在编译期就能通过类对象找到。而且这些地址固定不变,不需要执行期介入。
存储建构:
- 由编译器在每个类对象中安插一个指针指向该表格。
- 每个虚函数生成一个表格索引值,帮助表格寻找地址。
PS:表类似一个数组,索引值即下标,元素是虚函数地址。
(编译器立大功。)
这些都是编译期工作。执行期只是通过 virtual table slot (那些索引)找到地址,然后触发虚函数。
关于虚表的详细探讨:
一个class 只有一个虚表,每个表里有积极虚函数实例地址。
积极虚函数(active virtual func):
这一class所定义的函数实例。它会改写一个可能存在的base class virtual function函数实例
继承自base class的函数实例。这是在derived class决定不改写virtual function时才会出现的情况(也就是单纯的继承)
一个pure_virtual_called()函数实例(纯虚函数,没有内容),可以用来保存纯虚函数的空间,或当作执行期的异常处理函数等。
举个例子:
1
2
3
4
5
6
7
8
9
10
11class Point {
public:
virtual ~Point();
virtual Point& mult(float) = 0;
float x()const { return _x; }
virtual float y() const { return 0; }
virtual float z() const { return 0; }
protected:
Point(float x = 0.0);
float _x;
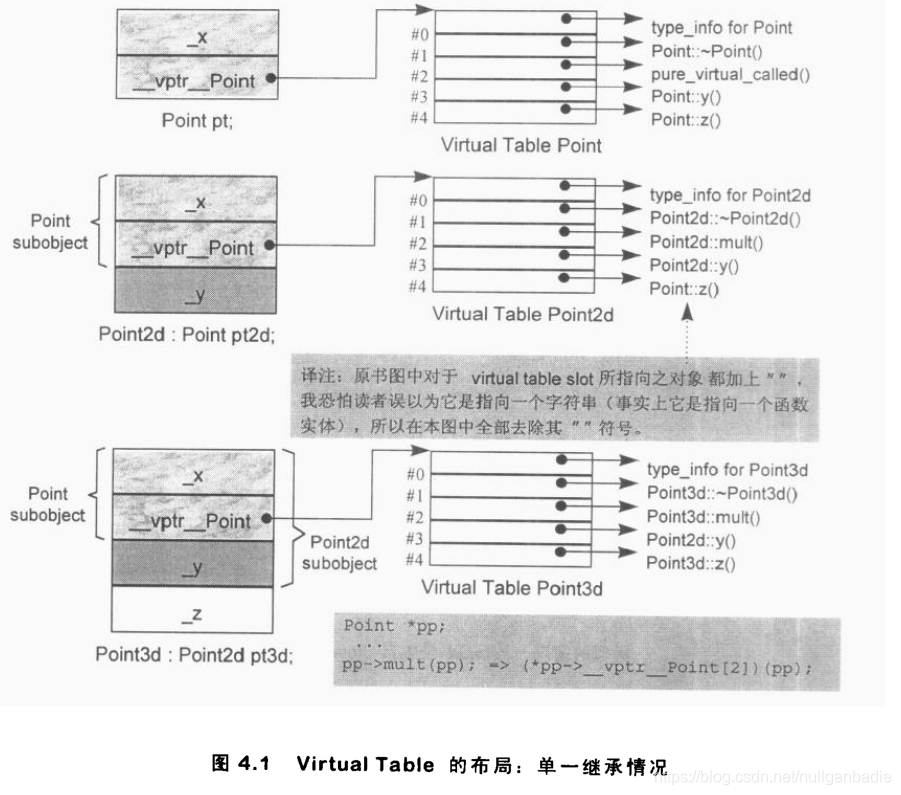
};
- ptr所指对象的真实类型,方便找到正确的实例(如
解释:虚析构函数生成 slot 1,mult() 生成 2,y() 和 z() 分别为 slot3 slot4。
x()不是虚函数,没有slot。
PS:mult()作为纯虚函数,没有定义。如果意外调用,直接结束掉。
继续深入一下,找个 class 继承 Point 会是什么结构呢?
1 | class Point2d :public Point { |
一共又三种可能性:
1.它可以继承base class所声明的virtual functions的函数实例。正确地说是,该函数实例的地址会被拷贝到derived table的相对应slot之中。比如上图中的#4位置
2.它可以使用自己的函数实例,也就是在base class中的virtual function上做改变了。这表示它自己的函数实例地址必须放在对应的slot之中。比如上图中的#2、#3位置
3.它可以加入一个新的virtual function。这时候virtual table的尺寸会增大slot,而新的函数实例地址则会被放入该slot之中
( Point2d的virtual table在slot1中指出析构函数,而在slot2中指出mult()(取代纯虚函数)。它自己的y()函数实例放在slot 3中,继承自Point的z()函数实例地址则被放在slot 4中。 )
继续继承:
1 | class Point3d :public Point2d { |
其virtual table中的slot 1位置放置Point3d的destructor,slot 2放置Point3d::mult()函数地址,slot 3放置继承自Point2d的y()函数地址,slot 4放置自己的z()函数地址。
现在,让我们再次面对ptr->z();
如何在编译期设定虚函数的调用?
可以解答如下了:
1.一般而言,在每次调用z()时,我并不知道ptr所指对象的真正类型。然而我知道,经由ptr可以存取到该对象的virtual table。
2虽然我不知道哪一个z()函数实例会被调用,但我知道每一个z()函数地址都被放在slot4中,从上面的图可以看出来。
由这两条信息使得编译器可以将该调用转化为:
1 | (*ptr->vptr[4])(ptr); |
这是单一继承下,虚函数的实现过程。
多重继承下的虚函数
- 编译期实现多态的困境
多重继承中虚函数的复杂度,主要来源于第二个或后续基类和执行期 this 指针的调整。
示例:
1 | class Base1 { |
让 Derived 支持虚函数困难度落在了 Base2 子对象上。
这里我的理解是,Base1和Derived的指针位置是一样的,都为0;而Base2指针的指向地址则>是
0 + sizeof(base1)。
这时我们面前有三个问题:1.虚析构2.继承而来的Base2::mumble()3.一组clone()函数实例。
这时,我们尝试多态操作:
指针赋值
1 | Base2 *pbase2 = new Derived; |
删除
1 | delete pbase2; |
这里出现了问题:指针必须再次调整,因为要指向Derived对象的起始处。但这个指向涉及的偏移量操作已经不能在编译期设定,因为 pbase2 指向的真正对象根本确定不了(该死的多态),除非在执行期。
1、这里是开头所说的问题之一:虚析构。
delete pbase2的时候Derived,Base1,Base2的析构函数都要被调用。
因为一个Derived对象中含有Base1和Base2的subobject,所以也需要调用它们的析构函数销毁它们的对象并释放内存空间(当然只有析构函数是这样)。
父类子对象可能有很多种多态情况,因此我们无法确定其指向的真正对象,(不同对象的偏移量不同),所以不能在编译期准确调用其析构函数。
2
3
4
5
6
7
//两个new返回的都是首地址:子类子对象在地址0处,父类子对象在0+sizeof(Base2)处
Base2 *pbase2 = new Derived; //该情况不需要偏移(甚至不需要this)
Base2 *pbase2 = new Base2; //该情况需要偏移
//于是编译器处理的两种结果不同
(*pbase2->vptr[1])(pbase2 + offset???)而且有无偏移量是一种情况,偏移量是多少又是一种情况(比如后续基类的Base3,Base4 …)
另外,调用虚析构函数时 this 指针发生了偏移(指向pbase2 到 指向 derived ,因为你需要调用人家的函数)。我既需要调整后的derived对象的起始地址,我又需要调整前的
pbase2::vptr,来指向子类析构函数实际地址。这里出现矛盾:我同时需要调整前后的信息。编译器如何实现的情况,我的理解是:
1.调整前先通过pbase2找到vptr中Derived的析构函数地址,
2.隐式地传this指针时才会调整指回整个Derived对象的起始地址,像这样:
2
//左括号调整前,右括号调整后
- 执行期解决方案:替代加大虚表的方法:==thunk设计==
执行期解决的一般的思路是,通过第二或后续的基类指针调用子类虚函数。 该操作必需的“this指针调整”操作,必须在执行期完成。
这意味着,操作的信息:offset的大小,以及把offset加上this指针的那一小段代码必须由编译器安插在某个地方。
问题是,在那个地方?
最自然(最笨)的方法是,都塞到虚表里,把虚表加大,来容纳这些偏移信息和地址。
虚表的 slot 也从整型之类的数字类型变成了结构体。
2
3
4
//改变为:
(*pbase2->vptr[1].faddr)
(pabse2 + pbase2->vptr[1].offset)
毫无疑问,太大了。不需要这些信息的空间也被塞满了。
thunk:主角登场
thunk是一小段汇编代码,实现:1.调整this指针偏移量 2.跳到目标虚函数中
1 | pbase2_dtor_thunk: |
所以可以暂时将thunk理解成一个函数,它是对上述两点操作的封装(调整this指针和调用对应的函数),只不过它是用汇编语言写才有效率可言。
thunk 让 虚表 slot 内含一个简单指针,要么指向虚函数,要么指向一个thunk(也就是要调整this指针时)。
但一个问题是,就如我们分析编译期局限性时一样,可能有多个不同继承层级的对象来调用同一个析构函数,这时的偏移量是不同的,对应slot也不同。
最高层级且处于最左侧的类对象,甚至不需要偏移量——它和子类对象的起始地址一样。这时slot直接放真正的调用函数地址就好了。
多重继承下,一个派生类内含n-1个额外的虚函数表,n表示上一层基类的数目(因此单一继承不会有额外的虚函数表)。如果子类有额外的虚函数,会存放在第一个基类的虚函数表里。
对本例Derived而言,编译器会产生有两个虚函数表。 分别对应 Base1 和 Base2 。针对每个虚表,子类对象都会有专门的 vptr ,且这些 vptr 会在构造函数中被赋初值(编译器的工作喽)

于是子类对象地址赋给子类指针或父类指针,就会产生多态效果——根据不同的类型,用不同表格来处理。
执行期链接器处理符号链接这种东西可能有点慢。一个思路是将多个虚表连接成一个:次要表格(次要仅从继承顺序上说)的获取只需要主要表格地址加上偏移量。
后续基类影响虚函数运行的==三种情况==
这三种情况在上面的图里有所反映
通过指向同层、次级父类的指针,调用子类虚函数
1
2
3
4Base2 *ptr = new Derived;
//调用Derived::~Derived
//ptr要减去sizeof(Base1)个bytes
delete ptr;之前已经讨论过,为了正确执行,ptr必须调整指向子类对象的起始处 (整个对象地址的 0)
通过指向子类对象的指针,调用同层、次级父类继承而来的父类自己的虚函数
1
2
3
4Derived *pder = new Derived;
//调用Base2::mumble()
//pder要加上sizeof(Base1)个bytes
pder->mumble();第一种情况的逆向。到父类子对象那里调用父类的虚函数
允许一个virtual function的返回值类型有所变化,可能成为base type,也可能是publicly derived type。
1 | Base2 *pb1=new Derived; |
Derived::clone()传回一个Derived类指针,改写了它的两个基类的函数体。当我们通过指向第二个基类的指针来调用clone()时,this指针的offset问题就会产生:
当进行pb1->clone()时,pb1会被调整指向Derived对象的起始地址,所以调用的是Derived::clone()。它会传回一个指针,指向一个新的Derived对象,该对象的地址在被指定给pb2前,必须先经过调整,以指向Base2 subobject。
书中还提供了两种提高效率的方法,一种是sun编译器的”split function”,一种是微软的“address points”
虚继承下的虚函数
1 | class Point2d { |

图右下角的两个vtbls内容有错。至少mumble()应该是Point2d::mumble 而不是 Point3d::mumble。
此例反映出的唯一有用的信息便是虚继承下的内存空间排布和正常继承不一样,并且一旦虚基类中虚继承了另一个虚基类,整个内存空间会非常混乱。this 指针的调整就会复杂难辨。
所以我们的启示只有一个:不要再虚基类里声明 nonstatic data members 。
指向成员函数的指针
nonstatic 成员函数 和 nonstatic 成员变量与类对象的绑定
- 取非静态成员变量的地址,是它在类中的相对byte位置(可能+1),这个offset需要类对象的地址,也就是绑定关系。
- 取非静态成员函数的地址,如果函数为non-virtual,它就和成员变量一样,是个绑定在类对象上的offset 地址。
对象地址来自 this指针 。
指向成员函数的指针
1
2
3
4
5
6
7
8
9
10
11
12
13
14//double是返回值类型
//Point::*说明是Point类成员,pmf是成员指针名
//最后的()是参数列表
double (Point::*pmf)();
//两种方法定义并初始化该指针的两种方法:
double (Point::*coord)() = &Point::x;
coord=&Point::y;
//调用的两种方法:
(origin.*coord)();
(ptr->*coord)();
//分别会被转换成(C++伪码)
(coord)(&origin);
(coord)(ptr);指向成员函数的指针的声明语法,以及指向“member selection”运算符(->或 .)的指针,这两部分的作用是为this指针保留空间。
所以静态成员函数的类型是函数指针,因为他们不需要 member selection ,更不需要 this指针。
在没有虚函数,多重继承,虚拟继承的情况下,编译器可以让 使用成员函数的指针与使用非成员函数的指针 的==效率相同==。
支持“指向虚拟成员函数”的指针
需求场景
1
2
3
4
5
6//z()是个虚函数
(Point::*pmf)()=&Point::z;
Point *ptr=new Point3d;
ptr->z(); //调用Point3d::z()
(ptr->*pmf)(); //调用Point3d::z()ptr 调用 z(),被调用的是 Point 3d::z();
ptr 通过 pmf 调用z(),被调用的还能是 Point3d 中的 z 吗?
答案是肯定的。
实现方法
首先,虚函数真正地址在编译期未知,只能知道它的 virtual table slot。
1
2
3
4
5
6
7
8
9
10
11
12
13
14class Point{
public:
virtual ~Point();
float x();
float y();
virtual float z();
};
&Point::~Point; //得到虚函数表里的索引1
&Point::x(); //得到内存地址
&Point::y(); //得到内存地址
&Point::z(); //得到虚函数表里的索引2
//通过 pmf 调用 z(),会被内部转化为编译期的式子:
(*ptr->vptr[(int)pmf])(ptr); //大概是这个样子了于是函数指针就有了两个意义:普通成员函数的内存地址和虚函数的slot专属版。
1
2//pmf内部定义
float(Point::*pmf)();这个函数要具备能寻址两种类型的成员函数的能力:
1
2
3float Point::x() { return _x;} //一长串吧
float Point::z() { return 0;} //小串
//都可以指定给 pmf于是pmf有两个功能:
- 能持有两种数值(注意不是同时)
- 能区分这个数值是内存地址还是虚表索引值
cfront2.0的解决办法:
1
2
3
4
5(((int)pmf)&~127)
?
(*pmf)(ptr)
:
(*ptr->vptr[(int)pmf](ptr));这个实现只能应用在继承体系中最多只有128个虚函数的情况。
多重继承下,指向成员函数的指针
如题,怎样让指向成员函数的指针在多重继承下可行?
Stroustrup的方法:
1 | struct __mptr { |
缺点:
检查成本高
Microsoft把这项检查拿掉,导入一个它所谓的vcall thunk。
在此策略下,faddr被指定的要不就是真正的member function(如果函数是nonvirtual的话),要不就是vcall thunk的地址。
于是virtual或nonvirtual函数的调用操作透明化,vcall thunk会选出并调用相关virtual table中适当的slot。
传递一个不变值指针给成员函数时,它需要产生一个临时对象
举例子:
1
2
3
4
5
6
7
8
9extern Point3d foo(const Point3d& , Point3d (Point3d::*)());
void bar(const Point3d& p ){
Point3d pt = foo(p,&Point3d::normal );
}
//&Point3d::normal 的值类似这样:
{0 , -1 , 10727417}
//需要产生临时对象,有明确初值
_mptr temp = {0 , -1 , 10727417} //伪码
foo(p,temp);
回到开始的那个结构体:
delta字段表示this指针的offset指针,而v_offset字段放的是一个virtual base class(或多重继承中的第二个、第三个等等)的vptr位置。
如果vptr被编译器放在class对象的起头处,这个字段就没什么必要了:这些字段在多重继承或虚拟继承的情况下才有必要性。
有许多编译器在自身内部根据不同的classes特性提供多种指向member functions的指针形式,例如Microsoft就供应了三种针对:
- 一个单一继承实例(其中带有vcall thunk地址或是函数地址)
- 一个多重继承实例(其中带有faddr和delta两个members)
- 一个虚拟继承实例(其中带有四个members)
内联函数
加了inline关键字,函数不一定就是内联函数。
编译器真的相信它可以扩展成inline函数时,其执行成本比一般函数调用和返回机制带来的负荷要低。
编译器处理inline函数,有两个阶段:
分析函数定义和复杂度,编译器会判断能否成为inline函数。
如果函数成不了inline ,就会转成一个static函数,并在被编译模块内产生对应函数定义。
真正的inline函数扩展操作是在调用的那一点上,这会带来参数的求值操作以及临时性对象的管理。
Formal arguments
inline 函数扩展期间,形参会被实参替代。
但无脑替代实参决定是有副作用的,比如一些表达式的重复求值之类的。
1 | inline int min(int i,int j){ |
Local variables
加入一个局部变量,类似int minval
1 | inline int min(int i,intt j){ |
如果 inline 函数以单一表达式扩展多次,则每次扩展都需要自己的一组局部变量。
inline 函数以分离的多个式子被扩展多次,那么只需要一组局部变量求值就能重复使用。
inline 函数扩展后的局部变量,再加上有副作用的参数,可能会导致大量临时性对象的产生,特别是它以单一表达式被扩展多次的话,例如:
1 | //例如: |
两个特性
- inline 函数可以有效存取封装于class中的nonpublic数据,同时也是#define的一个安全代替品。
但其弊端是,一个inline函数如果被调用太多次,会产生大量的扩展码,使程序的大小暴涨。
- inline里再有inline可能因为连锁复杂度扩展不出来。
所以你需要小心处理 inline 函数
返回一个即将销毁的局部对象,像这样:
1 | X bar() |
cfront做法:
- 加上一个类型为类对象引用的额外参数,用来放置拷贝构造出的返回值。
- return 前穿插一个拷贝构造的操作:利用传回值(例子中的
xx)初始化上面增加的额外参数。
于是我们希望得到的局部对象值,在真正的返回值返回通过额外参数返回了;而真正的返回值呢?
1 | void bar(X& __result) //额外参数 |
接下来转换每个bar()调用操作:
1 | X xx = bar(); |
概括来说:用一个载体来 copy 对象(已经有载体了就作为参数)。