第3章 Data语意学(The Semantics of Data)
一个 library
1 | class X{ }; |
在这个继承体系下,X 、Y 、Z 、A 各自的大小不是0,而分别是:1、8 、 8 、12(byte)。
原因:
对于X:X大小为1,是因为编译器不允许==独立== class 占用内存为0。它在 class X 中偷偷插入了一个 char 指针。
对于Y、Z:
语言本身的 overhead :为了支持 virtual base class , 类内会插入一个 vptr 指针来指向相关 virtual table。
table 里存放 virtual base class subobject 的偏移地址或实际地址。
X 的 char 指针被偷偷继承了,此时子类大小为 1+4 = 5 byte 。
这里许多编译器会对这个char指针进行优化,但该例中没有。
Alignment 齐位要求导致 5->8 byte。
32位计算机的内存齐位大小:4byte
许多编译器对继承来的 空白基类char指针会进行优化。
(优化后,Y和Z 只剩一个指针的大小为 4 byte)
优化方式:EBO ,让空白虚基类作为子类对象开头的一部分(不花费任何空间)
对于 A:virtual base class 不会让A的内存变成简单的 8+8=16。
至于为何变成12:
- 虚基类的subobject(子内容)占 1 byte。
- Base class Y 和 Z 减去了vptr 的大小为4 byte,4+4=8byte
- class A 自己的大小为 0
- 齐位要求:9->12 byte 。
如果编译器有EBO,大小则为 8 byte。
(如果虚基类里本身有数据(一个以上),EBO就会失效,两种编译器的对象布局会完全相同)
另外
C++Standard 不强制规定 base class subobject 的排列顺序或 不同存取层级的 data member 顺序。
它也不规定 virtual function 或 virtual base class 的实现细节。它认为这些应该交给厂商决定
这一章中有两个关键点:class中的 data members 和 class hierarchy 。
class.data members能够表现 class 的状态:
Nonstatic data member 放置的是针对个别 object 的数据。数据和对象的内存在一起。
static data member 放置的是针对整个类(共享)的数据。数据被放置在 global data segment 中。它永远只有一份实例。
即使 class 没有任何 object ,static data 也存在。这一点在template class 中稍有不同。
Nonstatic data 的设计考虑到了与 C-struct 的兼容。
编译器为实现 virtual 等会加上许多额外 data member ,加上边界需要,内存往往比想象中更大。
3.1 The Binding of a Data Member
从编译器角度探索代码实现的一些过程
1 | //某个foo.h头文件 |
在今天的编译器下,point::X()传回 class 内部的x。早期编译器为了防止指向 global x object ,有两种设计思路。
所有data member 放在开头,来确保正确绑定。
1
2
3
4
5
6class Point3d
{
float x,y,z; //看到它们了
public:
float X() const {return x;} //不怕被外部引入调用了!
}把所有 inline function 放到类的声明之外。
1
2
3
4
5
6
7
8
9
10classs Point3d
{
public:
Point3d();
float X() const;
void X(float) const; //编译器只看到了声明,看到下面的内部变量后再去实现
...
}
inline float Point3d::X() const {return x;}放到实现外
...
这两个古老思路被称为 member rewriting rule ,不允许 inline 函数实体在 class 声明被完全看见之前去进行 evaluate。
C++ Standard 以 member scope resolution rules 来更好完成 rewriting rule 。
效果:inline function 在class声明后被立刻定义,仍然对其评估求值。
2
3
4
5
6
7
8
9
class Point3d{
public:
...
void X(float new_x)const { x=new_x; }
//对于函数本体的分析将延迟到编译器发现 class 的 “}” 时
private:
float x,y,z;
};对member function 的本体分析,直到整个 class 声明都出现才开始。这时不需要把所有类内部函数实现转移到类外部了。
特殊情况:member function 的 argument list
1 | typedef int length; //重命名类型了 |
非我们所愿的数据绑定情况在两个参数第一次被编译器看到时,仍然会发生。上面的两个 length 类型 都被 resolve 成 global typedef 了。
这样一来,后续在去 nested - typedef length,就会导致编译器报错并定义最早的绑定不合法。
所以,把嵌套的 typedef 放到 class 起始处吧。
3.2 Data Member Layout
1 | class Point3d{ |
non-static data member 在 class object 中的排列顺序和其被声明的顺序一样。
任何中间介入例如freeList和chunkSize的static数据成员 都不会被放进对象的布局之中。
在上述例子中,每一个Point3d的对象由3个float组成,次序是x,y,z
static数据成员存放在程序的数据段中,属于整个类,不属于某个对象。
C++ Standard要求,在同一个access section(也就是private,public,protected等区段)中,只需要满足**“较晚出现的数据成员在对象中有较高的地址”**即可。
即在同一个acess section中,次序按照声明的次序,但是不一定连续,可能因为齐位调整(alignment)或者编译器自动合成的一些内部使用的数据成员,如虚函数表指针vptr插入到这些数据成员到中间。
(传统的编译器会把vptr放到所有明确声明的数据成员最后,当然也有编译器放在对象的最前端。总之C++ Standard 对这种布局很宽松啦)
对于不同access section的情况:
1 | class Point3d{ |
大小和组成同先前的一样。排列顺序由编译器决定。
主流想法是:把一个以上的 access section 连锁在一起,按照声明顺序形成连续区块。
Access section 的多寡没有额外负担。8个section中的8个member 和1个 section 中的8个 member 大小一样。
拓展
一个能判断谁先出现在 class object中的 template function。
(两个 member 都是不同的 access section 中第一被声明者,此函数就可以用来判断哪一个 section 先出现)
1 | template< class class_type, |
1 | access_order(&Point3d::z , &Point3d::y); |
3.3 Data Member的存取
1 | Point3d origin; |
下面来根据根据不同情况分析 x 的存取成本。
分析前的一个问题
1 | Point3d origin, *pt = &origin; |
通过 origin 存取和 通过 pt 存取 有什么差别吗?
稍后会回答。
Static Data Members
前面讲过,每一个static成员只存在一个实体,存放在程序的data segment数据段中,被视为一个global变量(只在class存在范围内可见)
1 | origin.chunkSize=250; //这样调用,内部转化为: |
通过 member selection operators(“.”运算符)对 静态成员变量进行操作只是语法上的简便操作。实际上static-member 并不在 class 对象中。所以存取 static member 并不需要通过 class 对象。
chunksize是继承来的member
各种复杂关系,比如虚基类的虚基类那里继承而来。。。
不会发生任何变化。static-member 仍然在栈里等待着。
static data member 通过函数调用
一种可能的转化(不同标准不同处理)
1 | foobar().chunkSize=250; //这样调用,内部转化为: |
取静态成员变量地址
因为 static member 不内含在 class 对象里,取其地址不会得到指向对应 class member 的指针,而会得到指向其本身数据类型的指针。
1 | &Point3d::chunkSize; //得到 const int* 类型的内存地址 |
对于静态成员冲突:
如果一个程序里定义了两个类,两个类都声明了一个static成员,且两个static成员同名,那么都存放在程序的数据段中时会引起同名冲突。
编译器会暗中对每一个static成员编码,得到一个独一无二的程序识别代码(一起扔到某个表格之类的东西里),这种手法叫name-mangling(不同编译器编码不同)。主要做两件事:
1、一种算法,推导出独一无二的名称
2、推导出的名称能够还原(万一编译系统(或环境工具)必须与使用者交谈,那么那些独一无二的名称 可以轻易被推导回原来的名称)
Nonstatic Data Member
non-static成员存在于每一个对象中,必须通过显示的或者隐式的对象才能对non-static成员进行存取。
只要程序员在成员函数里直接处理non-static成员,隐式的对象就会出现(它就是被编译器隐藏的家伙)。
1 | Point3d::translate(const Point3d &pt){ |
implicit class object 由 this 指针表达。
对 nonstatic data member 进行存取操作时,编译器会要求 class object 的起始地址 + offset(data member)偏移地址 。
1 | origin.y = 0.0; |
- -1是为了让系统区分指向成员变量的指针中,空指针和指向第一个变量的指针(两者都是0)
- nonstaic 成员变量的offset在编译期就能得知。即使该 member 属于 base class subobject(继承来的子内容)。因此存取效率和 C struct 成员 或独立类中的 成员 是一样的。
虚拟继承
1 | Point3d origin; |
虚拟继承使 base class subobject 存取 class members 增加了新的间接性。
(指针的间接性 + virtual vptr 间接性)
当然,x 在作为 struct 成员,独立类成员、普通继承(非virtual)成员的效率都相同。
但在作为我们当前讨论的 virtual base class 时,存取速度会稍慢。
这时就回到了该节开头的那个问题:以上两个存取方式有什么重大差别?
答案:当Point3d为子类,继承过一个 virtual base class,而 member(如x)又属于这个虚基类时,差别就会很大:
- pt由于间接性,不能确定指向哪一种 class type ,于是在编译期就无从知晓该成员的偏移位置。所以这个存取操作被转移到了运行期(通过额外的间接索引来解决)。
- origin 不会存在pt的问题,他的类型很明确,即 Point3d class。即使它继承自虚基类,成员偏移量也能够在编译期固定。
戏份更多的编译器甚至能通过 origin 静态解决掉对x的存取操作。
3.4 继承与 Data Member
CPP继承模型中,一个子类对象表现出来的东西,是 derived class member 和 base class member 的总和。但这两者的排列顺序并没有明确规定。
通常 base class members 先出现,属于virtual base class 的部分除外。
1 | class Point2d{ |
下面我们将在以上两个独立类之间的关系上做文章,分别讨论:“单一继承且不含 virtual function”、“单一继承并含virtual functions”、“多重继承”、“虚拟继承”的情况。
先看下独立类时的状态(non-virtual function)

和 C struct 完全一样
只要继承不要多态
现在从Point2d派生出Point3d,于是Point3d将继承x和y坐标的一切(包括数据实体和操作方法),使Point无论2d或3d都可以共享数据本身和数据的处理方法。
一般而言,非虚拟继承并不会增加空间或存取时间上的额外负担。
1 | class Point2d{ |
普通继承的好处是负责坐标点的程序代码能够局部化,同时能够表现出两个 class 的紧密关系。即使两个类独立出来,也不需要改变声明和使用。

但这种设计有两个坑:
这种继承关系需要选择某些函数作为 inline 函数,否则就会出现相同操作的函数重复出现。
如示例中的 operator += 和 constructor 函数:
Point3d object 的初始化和加法操作,需要部分point2d 和 部分 point3d 作为成本。
将一个类拆分成两层或者更多层的类时,为了表现”类体系的抽象化“而造成空间膨胀。
以 concrete 类为例
2
3
4
5
6
7
private:
int val;
char c1;
char c2;
char c3;
};空间分析(32bit):val - 4byte , c1 , c2 ,c3 各占用 1byte;齐位要求:4+3→8byte
这个案例中如果有以下应用场景:将 concrete 分裂成三层结构
1 | class Concrete1{ |
空间膨胀喽:三次齐位要求造成内存为 8+4+4 = 16 byte
不要想当然认为 concrete::nonstatic data member bit2 会填补 concrete1的空间。齐位填充会提前发生。
那么这种提前填充,或者说没有把子类和父类子对象填充在一起的设计用意何在呢?
看看这个例子:
2
>Concrete1 *pc1_1 , *pc1_2; //这俩可以指向上述三种classes object。发生下述操作时:
应该执行一个默认的 memberwise 复制操作,来一个一个复制 Concrete1的member 。
如果pc1_1 指向一个 Concrete2 object 或 Concrete3 object 的话,上述指针赋值操作应将复制内容指定为 Concrete1 subobject。
但如果子类成员和父类子对象捆绑在一起,来填补空间的话,就会发生意外:
2
3
4
>//pc1_2
>pc1_1 = pc2; //令 pc1_1 指向 Concrete2 对象
>*pc1_1=*pc1_2; // pc1_1 的 derived class subobject 会被覆盖,使bit2被覆盖产生非预期上述操作会把Concrete1对象逐对象拷贝,包括==原本应该==padding的三个字节,于是实际pc1_1指向的Concrete2对象的bit2会被覆盖掉,出现一个无法确定的值。
下图为绑定后的过程 :

在子类中的 base class subobject 的原样性被破坏后,会导致 copy 时
Concrete 1 的子对象复制给 Concrete2, 破坏了 Concrete 2 (捆绑后) 的成员。
加上多态
多态嘛,处理一个坐标点而不在乎它是 Point2d 还是 Point3d ,在继承关系中提供一个 virtual function 接口。
1 | class Point2d{ |
既然多态,导入一个 virtual 接口才显得合理。
1 | void foo(Point2d &p1,Point2d &p2){ |
Point3d:
1 | class Point3d:public Point2d{ |
两个 z() member function 和 operator+=()运算符 都成了 virtual function
每一个Point3d class object 内含一个额外的 vptr member(from Point2d)
面向对象的弹性会带来相应的实现负担:
导入一个和Point2d有关的虚函数表,存放声明的虚函数地址,还有支持runtime type identification相关的东西。
每一个类对象要加一个虚函数表指针vptr,提供执行期的链接,使得每一个对象都能找到相应的虚函数表。
构造函数需要为vptr提供初始值,让它指向类对应的虚函数表。这可能意味着所有派生类和基类的构造函数都要重新设定vptr的值。
这些操作都是编译器偷偷做出的。
析构函数需要消除vptr。vptr很可能已经在派生类析构函数中被设定为派生类的虚函数表地址,析构函数的调用次序反向的,从派生类到基类。
负担程度视“被处理的Point2d objects 的个数和生命期”而定。同时也要考虑“多态设计取得的收益”。
vptr位置问题
编译器领域有一个讨论点:vptr 放置在 class object 的哪个位置。
- 放在尾端
1 | Struct no_virts{ |

好处:与 base class C struct 对象布局相兼容。
上例中,带有虚函数的继承布局(vptr在尾端)

- 放开头

vptr 在 class object 前端,对于多重继承场景,通过指针(指向类成员)调用虚函数有帮助:
class object 起始点开始测量计算的 offset 不需要在运行期准备了;与 class vptr 间的 offset 也不需要在运行期准备。
缺点:丧失了C语言兼容性。
老实说,这种兼容无关痛痒,谁会在 C struct 上派生出多态 class 呢?
多重继承
自然多态(natural polymorphism):单一继承中,父类和子类转换很自然,因为它们的继承对象起始地址相同,所以父类指针指向子类对象时,不需要编译器参与调整地址,效率很高。
non-virtual 基类下如果存在一个子类有 virtual function,就会失去单一继承的自然多态。这时,子类转为基类,就需要编译器介入来调整地址(因为vptr插入到了 class object 的起始处)。
多重继承中,子类和基类的关系并不那么“自然”。
1 | class Point2d{ |

对于这种多重派生对象,将其地址指定给最上层的 base class 指针时,情况和单一继承相同(父子指向相同地址,成本只有指定地址的操作)。
后续子类的地址指定操作,则需要手动调整地址。
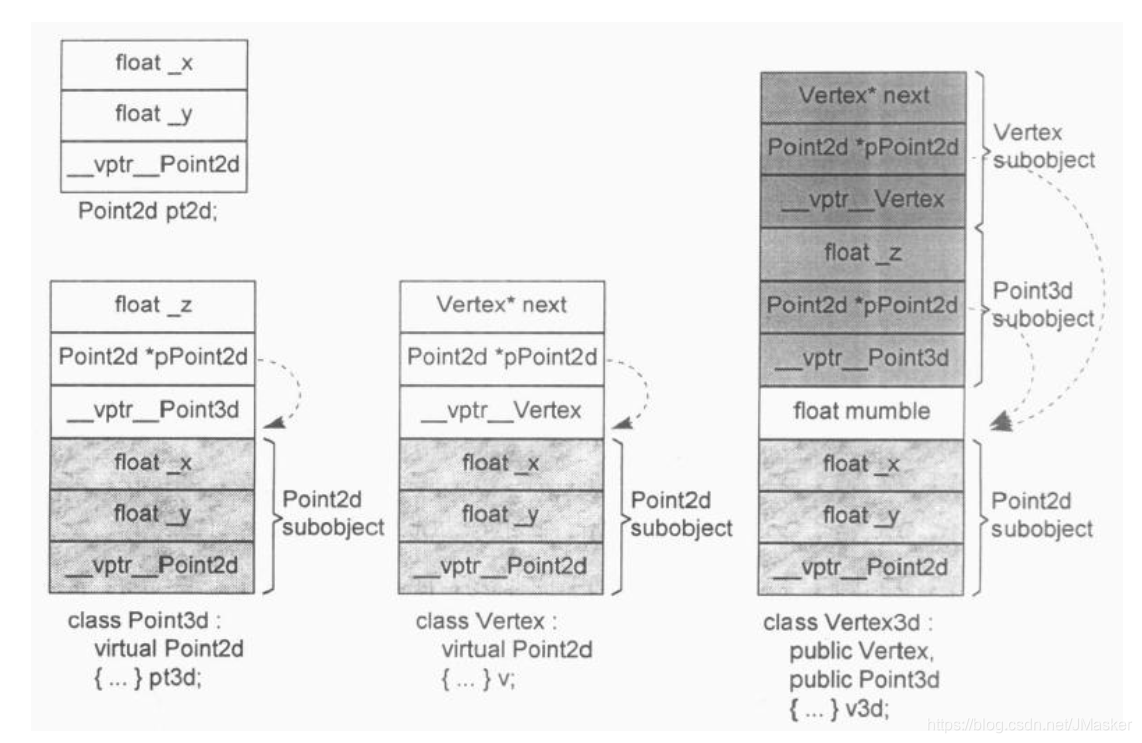
1 | Vertex3d v3d; |

C++ Standard 并未要求Vertex3d 中的 base class Point3d 和 Vertex 有特定排列顺序。
CFront 和许多编译器,按照声明顺序排列继承的基类:Point3d subobject + Vertex subobject + Vertex 3d subobject 依次存储。
(加上虚拟继承就不一样了)
存取第二层以上的基类的 data member ,只是一个简单的 offset 运算。
虚拟继承
虚拟继承的应用场景很狭窄,几乎是为解决多重继承的重复副本而生的。
1 | //多重继承 |

iostream 继承 istream 和 ostream 时,只需要一个 ios subobject。解决方法即虚继承。
虚拟继承的实现需要将 两个基类各自维护的一个 ios subobject 折叠成一个由共同子类维护的单一 subobject,同时保存好基类和子类各自的指针(引用)间的多态指定操作。
Class 继承体系出现 virtual base class subobject 后,会分割成两部分:
不变区域:这里的数据不管后续继承的变化如何,拥有固定 offset (从 object 开头),可直接存取。
共享区域:即virtual base class subobject 部分的数据,其位置随着每次的派生操作都会有变化,只能间接存取。
各编译器对间接存取的实现技术不同。
以下是三种 v-base-class-s 的间接存取策略。
- 指针实现
1 |
|
一般的布局策略是先安排好派生类中不变的部分,再建立共享部分。cfront编译器会在每一个派生类对象中安插一些指针,每个指针指向一个虚基类。要存取继承得来的虚基类成员,可以使用相关指针间接完成。
1 | void Point3d::operator+=(const Point3d &rhs){ |
每一个对象必须针对每一个虚基类背负一个额外的指针,但是我们希望每一个类对象的大小是固定的,不因为其虚基类的数量而变化。
解决方法:
1、微软的编译器里会引入虚基类表(类似于虚函数表),在继承虚基类的子类对象中,通过一个虚基类表指针指向虚基类表(虚基类指针存放在这些表格中)。
2、在虚函数表中放置虚基类的offset(而不是地址)。(作者实现时,将虚基类偏移地址和虚函数入口混杂在一起,通过正负值索引区分虚函数表中的地址:正数索引到虚函数,负数所引导虚基类)
下图显示了这种base class offset实现模型:
1
2
3
4
5
6
7>void Point3d::operator+=(const Point3d &rhs){
//这里_vptr_Point3d[-1]存放的是虚基类距离对象起始地址的offset
//this是对象起始地址,所以加起来就是虚基类的subobject
(this+_vptr_Point3d[-1])->_x += (&rhs + rhs._vptr_Point3d[-1])->_x;
(this+_vptr_Point3d[-1])->_y += (&rhs + rhs._vptr_Point3d[-1])->_y;
_z+=rhs._z;
>};//为了可读性,没有做类型转换,也没有先执行对效率有帮助的地址预先计算操作这种功能的成本只会在member使用的过程中消耗,所以属于局部性成本(虽然本身有点昂贵)。
示例:
1
2
3>Point2d *p2d=pv3d;
>//在上述实现模型下变成:
>Point2d *p2d=pv3d?pv3d+pv3d->_vptr_Point3d[-1]:0;每有一层虚拟继承,间接存取的层次就会加一层(三层继承,就要通过三个 virtual base class 指针进行三次间接存取)。我们希望每次存取时间都是固定的,不因为虚拟派生的深度而改变。
通过拷贝操作取得所有嵌套虚基类指针,将之放到子类对象中,这样就不用间接存取了,用空间换时间。下图显示了这种模型的实现:
区分
非多态的 class object 存取继承而来的 virtual base class 的成员:
1 | Point3d origin; |
可直接被优化为直接存取,在这次存取和下一次存取的过程中间,对象类型不可改变。
如同对象调用虚函数可以在编译器完成。
一般而言,虚基类最有效的一种运用方式就是:一个抽象的虚基类,没有任何数据成员。
3.5 对象成员的效率
1、直接存取对象成员和使用inline的Get和Set函数存取对象成员经过优化后效率一样。
2、除了虚拟继承情况外,1中的效率一样(包括单一继承的情况)。随着虚拟继承层数增加,1中存取对象的时间增大。
3.6指向数据成员的指针
1 |
|
实际上 offset 往往比 正常地址位置 多1,也就是说,如果vptr放在对象头端,三个坐标值在对象布局中的offset分别是1,5,9;如果vptr放在对象尾端,三个坐标值在对象布局中的offset分别是5,9,13。
(原因和3.3中non-static成员中-1的原因一样):为了区别一个类数据成员类型的指针是空指针和指向第一个offset为0的成员时的情形.
理解了指向成员变量的指针后,就可以明确下 & Point3d::z 和 & origin.z 的差别了。
- 取 nonstatic data member 的地址:得到它在类中的 offset
- 取 绑定在特定实例对象身上的成员地址: 得到它在内存中的真正 address
&origin.z减 z 偏移量 同时 加 1 ,即origin起始地址
& origin.z返回类型为 float* 而不是 float Point3d::*
在多重继承下,如果要将第二个或者后继的基类指针和一个“与派生类对象绑定”的成员结合起来,会在偏移量的问题上变得比较复杂:
1 |
|
当 (指向base2成员) 变量的bmp被作为func1()的第一个参数时,它的值就必须因介入的Base1 class的大小而调整,否则pd->*dmp将存取到Base1::val1,而不是希望的Base1:val2,要解决这个问题,必须经过以下过程:
1 | //经由编译器内部转换 |